
Storage Subsystem
Wir sind jetzt mit unserem Storage Subsystem am 8.8. im Grunde wieder dort, wo am 12.7. der große Ausfall passiert ist. Wir laufen jetzt wieder komplett auf der neuen Hardware. Was ist in der Zwischenzeit passiert? Nach dem Totalausfall des Disk Systems vom 12.8. wurde der Betrieb wieder zurück gebaut und alles lief wieder auf der alten Hardware.
Wir versuchen natürlich die Ausfallzeiten (durch Wartung aber vor allem durch Defekte) so gering wie möglich zu halten. Daher wird versucht alle Komponenten mindestens doppelt auszuführen. Das Storage Subsystem trifft dabei eine besondere Rolle. Denn den Storage kann man sich wie eine zentrale Festplatte vorstellen – auf dem alle Daten liegen. Wenn das Storage Subsystem nicht mehr funktioniert (bzw. die Daten weg sind) funktioniert gar nichts mehr.
Ausfallsicherheit
Danach wurde der Storage so umgebaut, dass es nun eine zweifache Redundanz gibt. D.h. die Daten werden alle 3x gespeichert. Dazu verwenden wir 100 Stück 300GB Festplatten + 4 x 1,6 TB SSD. 8 Platten werden als Hot Spares verwendet. D.h. die Platten springen ein, wenn eine andere Platte ausfällt. Von der Rohkapazität von 36,4 TB bleiben dann im Endeffekt nur noch rund 8 TB nutzbarer Platz übrig. Nach dem neuerlichen Umbau können jetzt also entweder 2 ganze Storage Systeme inklusive der Festplatten ausfallen, ohne dass das einen für den Benutzer Merkbaren Ausfall bewirken würde.
Sicherung
Zusätzlich werden die Daten von zwei unabhängigen Sicherungssystemen gesichert, damit wenn wieder so ein Ausfall passiert, wie das letzte Mal, die Daten wiederhergestellt werden können. Wir verwenden hier eine Sicherung, die die virtuellen Maschinen sichert, sowie ein Sicherungssystem, dass die kritischen Anwendungsdaten nochmals extra sichert.
Das Problem bei der Rücksicherung ist vor allem, dass sie Zeit benötigt. Es werden doch große Datenmengen benötigt. Wenn sie gelegentlich ein mehrere hundert Gigabyte großes File von Festplatte auf Festplatte kopieren, dann wissen Sie, dass das eine Zeit lang in Anspruch nimmt auch wenn man die Datei nicht über das Netzwerk bewegen muss.
Wir planen daher als nächsten Schritt den Storage so einzurichten, dass er im laufenden Betrieb mit einem zweiten Storage repliziert. Falls der Storage also wie vor einem Monat trotz aller Sicherheitsvorehrungen einen Ausfall erleidet, sollten wir in der Lage sein, ohne Rücksicherung den Betrieb relativ flott wieder aufzunehmen.
Überwachung
Wenn Komponenten ausfallen, dann muss man das sofort mitbekommen und darauf reagieren können. Das Dumme ist, dass es immer wieder vorkommt, dass wenn eine Komponente ausfällt, auch eine andere Komponente Probleme macht. Wir haben uns daher dazu entschieden eine Überwachungssoftware anzuschaffen, die verschiedenste Komponenten überwachen kann. Die Software heißt PRTG und wird von einem Softwarehersteller in Deutschland hergestellt. Wir werden darüber noch gesondert berichten.
Performance
Auf diesem Plattenplatz liegen die virtualisierten Festplatten der virtuellen Maschinen. Warum so viele Platten? Es geht beim Hosting von virtuellen Maschinen vor allem um Plattendurchsatz. Natürlich benötigt man auch ausreichend Plattenkapazität, das ist aber weniger das Problem. Ein Serversystem braucht (natürlich je nach Nutzung) so um die 100-200GB. Da gingen sich noch immer rund 50 Server auf 8 TB aus. Diese Server greifen alle auf den gleichen Storage zu. Daher gibt es relativ viele Schreib-/Lesevorgänge auf diesen Harddisks. Diese Zugriffe verteilen sich dann wieder auf die Anzahl der eingesetzten Disken. D.h. je weniger Harddisks im Einsatz sind, desto mehr Zugriff muss eine Disk vertragen. Irgendwann laufen die Disken dann in die Sättigung – und die Platte(n) können die Last nicht mehr verkraften. Die Zugriffe werden in eine Warteschlange (Queue) gestellt und müssen warten. Das gesamte System wird langsam.
Der Faktor, mit dem man also den Storage beurteilt ob er eine große Anzahl von Zugriffen gleichzeitig aushält nennt sich IOPS (Also Input / Output per Sekunde). Diese Zahl beschreibt wie viele Ein/Ausgabevorgänge der Speicher in einer Sekunde abarbeiten kann. Dafür gibt es Benchmarks. Wir haben den Benchmark auf unseren neuen Storage losgelassen und 110.000 IOPS bei 80/20 Lese/Schreibzugriff gemessen. Das ist für unsere Verhältnisse ein ausgezeichnetes Ergebnis. Um ein wenig einen Vergleich zu haben – eine 10k RPM SAS Harddisk hat ca. 75-100 IOPS.
Wir haben uns nun auch noch mit dem bekannten Disk Performance Tool Crystal Disk Mark einen Vergleich gemacht.
- Seq Q32T1: Sequential (Block Size=128KiB) Read/Write with 32 Queues & 1 Threads
- 4K Q8T8: Random 4KiB Read/Write with 8 Queues & 8 Threads
- 4K Q32T1: Random 4KiB Read/Write with 32 Queues & 1 Threads
- 4K Q1T1: Random 4KiB Read/Write with 1 Queues & 1 Threads
Sequentielle Zugriffe (d.h. Daten, die hintereinander auf der Disk liegen und der Reihe nach gelesen werden) kommen im normalen Betrieb eher selten vor, daher sind die Geschwindigkeiten bei den Random Zugriffen aussagekräftiger. Ramdom Zugriffe greifen auf unterschiedliche Daten an unterschiedlichen Stellen der Harddisk zu.
Der erste Test ist mit einer lokalen SAS Harddisk an einem Raid Controller. Crystal Disk Mark macht 4 unterschiedliche Tests:
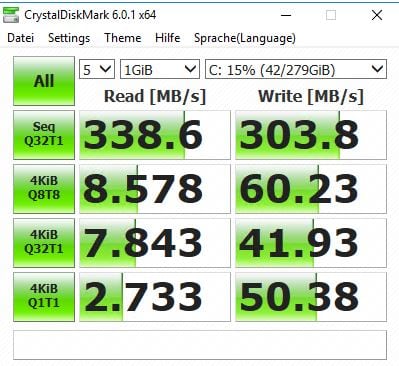 Der zweite Test ist eine SATA SSD am gleichen Raid Controller:
Der zweite Test ist eine SATA SSD am gleichen Raid Controller:
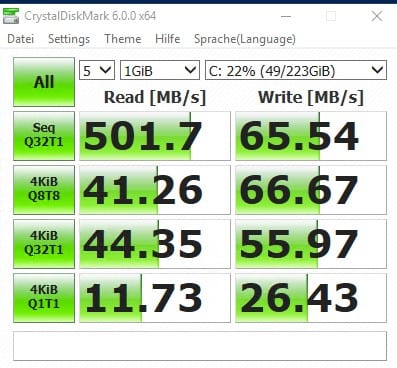 Wir sehen hier, dass die SSD im Lesebetrieb zwar deutlich schneller ist. Im Schreibbetrieb aber sogar hinter die Harddisk zurückfällt. Vor allem bei den Random Writes hat die SSD deutlich bessere Werte.
Wir sehen hier, dass die SSD im Lesebetrieb zwar deutlich schneller ist. Im Schreibbetrieb aber sogar hinter die Harddisk zurückfällt. Vor allem bei den Random Writes hat die SSD deutlich bessere Werte.
Wir testen nun auch unser neues Storage Subsystem:
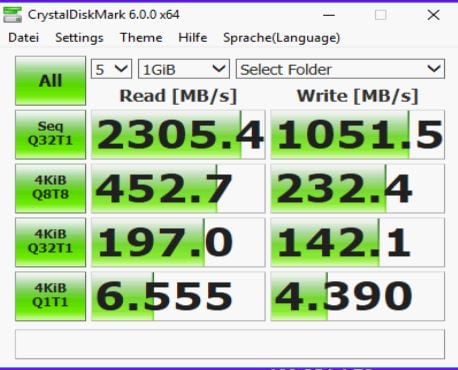
Wir sehen hier, dass wir bei allen Werten deutlich besser sind, als eine lokale SSD, außer beim letzten Test, wo der Storage ohne Parallelisierung seine Vorteile nicht ausspielen kann. Im Sequential Read sind wir aber fast 7 x so schnell wie eine lokale Harddisk und auch bei den 4k Random Read mit 8Ques und Threads sind wir 56 x so schnell wie eine lokale Harddisk.
Wir sollten nun mit dem neuen Storage Subsystem keinerlei Performanceprobleme im Disk Bereich mehr haben, und die Anwendungen die Disk Intensiv sind, sollten deutlich schneller geworden sein. Aus meiner Sicht merkt man das vor allem beim Webmail von Mailenable sehr deutlich, aber auch bei anderen Dingen sollte das merkbar sein.
Kosten
Bezüglich Kosten. Die Geschichte hat einen zweistelligen Tausend Euro Betrag gekostet. Wir haben fast ausschließlich gebrauchte Hardware verwendet, weil unser Budget neue Hardware nicht zulässt.

Werner Illsinger ist systemischer Coach, Unternehmensberater sowie Lektor an der FH-Kärnten. Sein Herzensanliegen ist es, dass Arbeit Spaß macht.